
并行程序设计: POSIX Threads
 ccrysisa
ccrysisaPOSIX (Portable Operating System Interfaces) is a family of standards for maintaining compatibility between operating systems. POSIX is a Unix-like operating system environment and is currently available on Unix/Linux, Windows, OS/2 and DOS.
Pthreads (POSIX Threads) is a POSIX standard for threads. The standard, POSIX.1c thread extension, defines thread creation and manipulation. This standard defines thread management, mutexes, conditions, read/write locks, barriers, etc. Except for the monitors, all features are available in Pthreads.
Process vs. Thread vs. Coroutines
With threads, the operating system switches running tasks preemptively according to its scheduling algorithm.
With coroutines, the programmer chooses, meaning tasks are cooperatively multitasked by pausing and resuming functions at set points.
- coroutine switches are cooperative, meaning the programmer controls when a switch will happen.
- The kernel is not involved in coroutine switches.
一图胜千语:

具体一点,从函数执行流程来看:
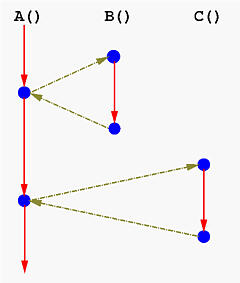
$\rightarrow$ 在使用 coroutinues 后执行流程变成 $\rightarrow$
C 语言程序中实作 coroutinue 的方法很多,例如「C 语言: goto 和流程控制篇」中提到的使用 switch-case 技巧进行实作。
这三个概念出现的时间与它们的复杂度正好相反,最复杂的 Process 最先出现,而最轻量的 Coroutines 反而最晚出现。
Thread & Process


- Wikipedia: Light-weight process
On Linux, user threads are implemented by allowing certain processes to share resources, which sometimes leads to these processes to be called “light weight processes”.
因为 Linux 在实作上故意混淆了 Process 和 Thread,所以一般不使用 Linux 作为 Thread 的解释案例
- Wikipedia: Thread-local storage
On a modern machine, where multiple threads may be modifying the errno variable, a call of a system function on one thread may overwrite the value previously set by a call of a system function on a different thread, possibly before following code on that different thread could check for the error condition. The solution is to have errno be a variable that looks as if it is global, but is physically stored in a per-thread memory pool, the thread-local storage.
PThread (POSIX threads)

POSIX 的全称是 Portable Operating System Interfaces,结合上图,所以你明白 pthread 的 P 代表的意义了吗?Answer
从 CPU 厂商群魔乱舞中诞生的标准,自然是要保证可移植 Portable 的啦 🤣
下面的这个由 Lawrence Livermore National Laboratory 撰写的教程文档写的非常棒,值得一读 (他们还有关于 HPC 高性能计算的相关教程文档):
Synchronizing Threads
3 basic synchronization primitives (为什么是这 3 个?请从 synchronized-with 关系进行思考)
- mutex locks
- condition variables
- semaphores
取材自 Ching-Kuang Shene 教授的讲义:
Conditions in Pthreads are usually used with a mutex to enforce mutual exclusion.
mutex locks
| |

- Only the owner can unlock a mutex. Since mutexes cannot be copied, use pointers.
- If
pthread_mutex_trylock()returnsEBUSY, the lock is already locked. Otherwise, the calling thread becomes the owner of this lock. - With
pthread_mutexattr_settype(), the type of a mutex can be set to allow recursive locking or report deadlock if the owner locks again
单纯的 Mutex 无法应对复杂情形的「生产者-消费者」问题,例如单生产者单消费者、多生产者单消费者、单生产者多消费者,甚至是多生产者多消费者 😵 需要配合 condition variables
我有用 Rust 写过一个「多生产者单消费者」的程序,相关的博客解说在 这里
condition variables
| |
- Condition variables allow a thread to block until a specific condition becomes true
- blocked thread goes to wait queue for condition
- When the condition becomes true, some other thread signals the blocked thread(s)
- Conditions in Pthreads are usually used with a mutex to enforce mutual exclusion.
- the wait call should occur under the protection of a mutex

使用 condition variables 改写之前 mutex 部分的 producer 实作 (实作是单生产者单消费者模型,且缓冲区有 MAX_SIZE 个元素):
| |
semaphores
semaphores 是站在「资源的数量」的角度来看待问题,这与 condition variables 是不同的
| |
- Can do increments and decrements of semaphore value
- Semaphore can be initialized to any value
- Thread blocks if semaphore value is less than or equal to zero when a decrement is attempted
- As soon as semaphore value is greater than zero, one of the blocked threads wakes up and continues
- no guarantees as to which thread this might be
mutex 在意的是 持有者,semaphore 在意的是 资源的总量,而 condition variables 在意的是 持有的条件。POSIX Threads

实例: 光线追踪
光线追踪 (Ray tracing) 相关:
- 2016q1 Homework #2
- UCLA Computer Science 35L, Winter 2016. Software Construction Laboratory
- CS35L_Assign8_Multithreading
光线追踪需要很大的运算量,所以我们可以自然地想到,能不能使用 pthreads 对运算进行加速,上面的最后一个链接就是对这种思路的实作。
编译与测试:
| |
预期得到下面的图:

可以将上面的 ./srt 命令后面的数字改为 1, 2, 8 之类的进行尝试,这个数字代表使用的执行绪的数量。另外,在 ./srt 命令之前使用 time 命令可以计算本次进行光线追踪所使用的时间,由此可以对比不同数量执行绪下的效能差异。
可以看下相关的程式码 main.c:
| |
显然是经典的 fork-join 模型 (pthread_create 进行 “fork”,pthread_join 进行 “join”),注意这里并没有使用到 mutex 之类的互斥量,这是可以做到的,只要你事先区分开不相关的区域分别进行计算即可,即不会发生数据竞争,那么久没必要使用 mutex 了。
POSIX Thread
Condition variables provide yet another way for threads to synchronize. While mutexes implement synchronization by controlling thread access to data, condition variables allow threads to synchronize based upon the actual value of data.
condition variables 由两种不同的初始化方式:
- 静态初始化 (static):
PTHREAD_COND_INITIALIZER - 动态初始化 (dynamic):
pthread_cond_init()
Synchronization
CMU 15-213: Intro to Computer Systems
- $23^{rd}$ Lecture Concurrent Programming

- $24^{rd}$ Lecture Synchroniza+on: Basics

| |
cnt 使用 volatile 關鍵字聲明,意思是避免編譯器產生的程式碼中,透過暫存器來保存數值,無論是讀取還是寫入,都在主記憶體操作。
細部的步驟分成 5 步:H -> L -> U -> S -> T,尤其要注意 LUS 這三個操作,這三個操作必須在一次執行中完成,一旦次序打亂,就會出現問題,不同執行緒拿到的值就不一定是最新的。也就是說該函式的正確執行和指令的執行順序有關
mutual exclusion (互斥) 手段的選擇,不是根據 CS 的大小,而是根據 CS 的性質,以及有哪些部分的程式碼,也就是,仰賴於核心內部的執行路徑。
semaphore 和 spinlock 屬於不同層次的互斥手段,前者的實現仰賴於後者,可類比於 HTTP 和 TCP/IP 的關係,儘管都算是網路通訊協定,但層次截然不同
System Programming wiki-book: Synchronization
Part 1: Mutex Locks
You can use the macro
PTHREAD_MUTEX_INITIALIZERonly for global (‘static’) variables.m = PTHREAD_MUTEX_INITIALIZERis equivalent to the more general purposepthread_mutex_init(&m,NULL). The init version includes options to trade performance for additional error-checking and advanced sharing options.
静态 (static) 初始化和动态 (dynamic) 初始化,其中静态初始化创建的是一个全局 (global) 的 mutex,而动态初始化则是对已有的 mutex 进行初始化设置
- Multiple threads doing init/destroy has undefined behavior
- Destroying a locked mutex has undefined behavior
- Basically try to keep to the pattern of one thread initializing a mutex and one and only one thread destroying a mutex.
mutex 的初始化和销毁需要注意只能调用一次,否则会导致 UB
This process runs slower because we lock and unlock the mutex a million times, which is expensive - at least compared with incrementing a variable. (And in this simple example we didn’t really need threads - we could have added up twice!) A faster multi-thread example would be to add one million using an automatic(local) variable and only then adding it to a shared total after the calculation loop has finished
有时候并不需要每次使用 mutex,这样会导致性能降低,分析程序的逻辑从而减少 mutex 的使用次数
Linux man page:
Part 2: Counting Semaphores
A counting semaphore contains a value[ non negative ] and supports two operations “wait” and “post”. Post increments the semaphore and immediately returns. “wait” will wait if the count is zero. If the count is non-zero the wait call decrements the count and immediately returns.
信号量的定义和的两种操作: wait 和 post,本质上都是对资源总量的操作
First decide if the initial value should be zero or some other value (e.g. the number of remaining spaces in an array).
创建信号量时也是需要先确定资源总量,例如数组元素的个数
Unlike a mutex, the increment and decrement can be from different threads.
信号量和 mutex 那种持有者才有权利进行释放的设置不同,信号量不存在持有者这一说法 (因为它是从资源总量进行考量的,自然不存在信号量的持有者这一概念),所以不同 thread 都可以对信号量进行操作 (通过 wait 和 post)
A mutex is an initialized semaphore that always
waitsbefore itposts
当信号量设定的资源总量为 1 时,它和 mutex 的功能十分相似,当然还需要保证使用时先使用 wait 在使用 post 操作,其功能才和 mutex 一致,否则会造成数据竞争 (先使用 post 会导致资源总量由 1 变为 2)
sem_postis one of a handful of functions that can be correctly used inside a signal handler. This means we can release a waiting thread which can now make all of the calls that we were not allowed to call inside the signal handler itself (e.g. printf).
| |
Linux man page:
Part 3: Working with Mutexes And Semaphores
Incrementing a variable (
i++) is not atomic because it requires three distinct steps: Copying the bit pattern from memory into the CPU; performing a calculation using the CPU’s registers; copying the bit pattern back to memory. During this increment sequence, another thread or process can still read the old value and other writes to the same memory would also be over-written when the increment sequence completes.
一个常见的数据竞争的例子
We will call these two semaphores ‘sremain’ and ‘sitems’. Remember
sem_waitwill wait if the semaphore’s count has been decremented to zero (by another thread callingsem_post).
在生产者和消费者模型中,通常是使用两个信号量来衡量资源总量,两个角度 (生产者和消费者) 来看待资源的可用量
However there is no mutual exclusion: Two threads can be in the critical section at the same time, which would corrupt the data structure (or least lead to data loss). The fix is to wrap a mutex around the critical section
信号量只能保证资源总量的正确使用,但无法生成更小精度 (例如针对某个元素) 的互斥区,此时需要搭配 mutex 来使用,即 semaphore 用于控制资源总量,mutex 用于保证特定资源的互斥。
Part 4: The Critical Section Problem
插旗表示此时由自己掌控,类似社团争斗,插旗表示主权:
| |
Candidate solution #1 also suffers a race condition i.e. it does not satisfy Mutual Exclusion because both threads/processes could read each other’s flag value (=lowered) and continue.
等待对方的 flag 降下,但是可能会同时看到对方的 flag 都为降下状态,进而导致都进入 CS
| |
Candidate #2 satisfies mutual exclusion - it is impossible for two threads to be inside the critical section at the same time. However this code suffers from deadlock!
谦让式: 升起自己的 flag 表示自己想要进入 CS,但如果对方的 flag 页升起的话,则进行谦让。如果双方同时升起 flag 的话,则会双方都进行谦让而导致死锁。
| |
Candidate #3 satisfies mutual exclusion (each thread or process gets exclusive access to the Critical Section), however both threads/processes must take a strict turn-based approach to using the critical section
按顺序进入 CS,类似于协作式多工,但因为需要严格遵循顺序,会导致即使对方不需要进入 CS,但为了保证顺序,需要让对方先进入 CS,然后自己才能进入 CS
There are three main desirable properties that we desire in a solution the critical section problem
- Mutual Exclusion - the thread/process gets exclusive access; others must wait until it exits the critical section.
- Bounded Wait - if the thread/process has to wait, then it should only have to wait for a finite, amount of time (infinite waiting times are not allowed!). The exact definition of bounded wait is that there is an upper (non-infinite) bound on the number of times any other process can enter its critical section before the given process enters.
- Progress - if no thread/process is inside the critical section, then the thread/process should be able to proceed (make progress) without having to wait.
| |
Imagine the first thread runs this code twice (so the turn flag now points to the second thread). While the first thread is still inside the Critical Section, the second thread arrives. The second thread can immediately continue into the Critical Section!
想要进入 CS 的线程需要先举起自己的 flag,如果对方没有升起 flag 或生起了 flag 但没到对方的顺序时,本线程可以直接进入 CS,否则需要按照顺序等待对方。这个方案看起来无懈可击,但由于这里的顺序会赋予线程进入 CS 的优先级,所以有些状况下并不符合互斥的要求
Peterson’s solution
Peterson published his novel and surprisingly simple solution in a 2 page paper in 1981.
| |
| |
This solution satisfies Mutual Exclusion, Bounded Wait and Progress. If thread #2 has set turn to 1 and is currently inside the critical section. Thread #1 arrives, sets the turn back to 2 and now waits until thread 2 lowers the flag.
Peterson 算法相比之前的方案只是将顺序的设定提前了,但却解决了之前方案的互斥问题,因为这样设定会使得 your flag is raised and turn is your_id 这个状态只可能出现在对方处于 CS 时,如果对方同时与自己争夺 CS 的进入权时,对方的状态是 your flag is raised and turn is my_id,从而将争夺进入权和已处于 CS 的 状态 进行了区分,解决了互斥问题。
Dekkers Algorithm (1962) was the first provably correct solution. A version of the algorithm is below.
| |
这个算法中的 flag 表示 CS 的进入权: 如果对方的 flag 未升起,则可以直接进入 CS,如果对方 flag 升起但不是对方的顺序,表示对方处于 CS 并且自己拥有接下来 CS 的进入权,所以需要等待到对方 flag 降下但同时可以不降下自己的 flag;如果对方 flag 升起并且是对方的顺序,表示是对方拥有 CS 的进入权,需要降下自己的 flag 进行谦让。
turn 在上面两种算法里的意义是不大相同的,具体请阅读论文获得背景知识的启发。
实际上不太会使用这两种算法来保证同步 (因为效能比较低),而是在设计硬件方面的同步机制 (例如同步原语) 时使用这两种算法来验证其功能的正确性
编译器和处理器的指令重排序功能使得纯软件的同步算法变得 too naive
However in general, CPUs and C compilers can re-order CPU instructions or use CPU-core-specific local cache values that are stale if another core updates the shared variables. Thus a simple pseudo-code to C implementation is too naive for most platforms.
Hardware Solutions
If interrupts are disabled then the current thread cannot be interrupted! i.e. the CPU instructions of the critical section will complete.
However most systems today have more than one CPU core and disabling interrupts is a privileged instruction - so the above technique is rarely appropriate.
| |
The exchange instruction must be atomic i.e. it behaves as a single uninterruptable and indivisible instruction. For example, if two threads both call
my_mutex_lock(and then __exch) at the same time, then one thread will receive a value of 0, and the other thread will loose and get the newer value of 1 (so will continue to poll).
How do we really implement the Critical Section Problem on real hardware?
A complete solution using C11 atomics is detailed here
- mutex_init
| |
- mutex_lock
| |
| |
- mutex_unlock
| |
Part 5: Condition Variables
What are condition variables?
Condition variables allow a set of threads to sleep until tickled! You can tickle one thread or all threads that are sleeping. If you only wake one thread then the operating system will decide which thread to wake up. You don’t wake threads directly instead you ‘signal’ the condition variable, which then will wake up one (or all) threads that are sleeping inside the condition variable.
Condition variables are used with a mutex and with a loop (to check a condition).
Occasionally a waiting thread may appear to wake up for no reason (this is called a spurious wake)! This is not an issue because you always use
waitinside a loop that tests a condition that must be true to continue.Threads sleeping inside a condition variable are woken up by calling
pthread_cond_broadcast(wake up all) orpthread_cond_signal(wake up one). Note despite the function name, this has nothing to do with POSIXsignals!
The call pthread_cond_wait performs three actions:
- unlock the mutex
- waits (sleeps until pthread_cond_signal is called on the same condition variable). It does 1 and 2 atomically.
- Before returning, locks the mutex
Condition variables need a mutex for three reasons.
The simplest to understand is that it prevents an early wakeup message (
signalorbroadcastfunctions) from being ’lost.’
A second common reason is that updating the program state (
answervariable) typically requires mutual exclusion - for example multiple threads may be updating the value ofanswer.
A third and subtle reason is to satisfy real-time scheduling concerns which we only outline here: In a time-critical application, the waiting thread with the highest priority should be allowed to continue first.
Why do spurious wakes exist?
For performance. On multi-CPU systems it is possible that a race-condition could cause a wake-up (signal) request to be unnoticed. The kernel may not detect this lost wake-up call but can detect when it might occur. To avoid the potential lost signal the thread is woken up so that the program code can test the condition again.
条件变量主要考虑 wait 方,即当条件不满足时需要进行 wait,又因为等待条件是双方都可以访问的,所以对于等待条件的访问/修改需要加上互斥锁 mutex 来保护,对于 signal 方就和普通的 mutex 使用类似,修改等待条件时需要加上互斥锁,然后条件满足时需要向 wit 方发送唤醒信号。总结一下条件变量的三大要素: 条件,互斥锁 以及用于唤醒/睡眠机制的 ConVar。
| |
| |
上面例子的三大要素分别对应为:
- 条件:
count - 互斥锁:
m - ConVar:
cv
原文后面的使用条件变量 (condition variables) 来实现信号量 (semaphore) 页可以通过这个三大要素进行分析,下面以 sem_t 结构体为例进行分析,sem_init, sem_post, sem_wait 这些函数留作练习:
| |
Part 6: Implementing a barrier
We could use a synchronization method called a barrier. When a thread reaches a barrier, it will wait at the barrier until all the threads reach the barrier, and then they’ll all proceed together.
屏障 (barriers) 可以实现多执行绪程序设计中经典的 fork-join 模型
Pthreads has a function
pthread_barrier_wait()that implements this. You’ll need to declare apthread_barrier_tvariable and initialize it withpthread_barrier_init().pthread_barrier_init()takes the number of threads that will be participating in the barrier as an argument. Here’s an example.
| |
多线程下的条件变量的使用,其本质和之前所提的三要素是符合的,因为每个线程只可能执行 if-else 部分的其中一个分支,而不同分支则分别代表了 post 和 wait 方法。
Part 7: The Reader Writer Problem
What is the Reader Writer Problem?
Multiple threads should be able to look up (read) values at the same time provided the data structure is not being written to.
to avoid data corruption, only one thread at a time may modify (write) the data structure (and no readers may be reading at that time).
Rust 的不可变引用 &T 和可变引用 &mut T 实作了这一点 🤣
| |
| |
实际上可以将 write 的条件变量的使用也像 read 分为两部分,但这样也只有一个 write 可以进入到 Write here! 处,实质上已经互斥了,所以就没必要分为两部分了。
Candidate #3 above suffers from starvation. If readers are constantly arriving then a writer will never be able to proceed (the ‘reading’ count never reduces to zero). This is known as starvation and would be discovered under heavy loads.
这种 多读单写 模型了另一个重要考量点是: write 线程可能会被 饿死 (starvation)
Our fix is to implement a bounded-wait for the writer. If a writer arrives they will still need to wait for existing readers however future readers must be placed in a “holding pen” and wait for the writer to finish. The “holding pen” can be implemented using a variable and a condition variable (so that we can wake up the threads once the writer has finished).
| |
| |
这样即使完成读操作的线程进行唤醒,在 write 线程后面抵达的 read 线程被唤醒也会因为不满足条件而进行睡眠等待,只有 write 线程才会对条件变量进行回应。
Part 8: Ring Buffer Example

| |
上面这段程式码看起来可以进行如下的重写:
| |
This method would appear to work (pass simple tests etc) but contains a subtle bug. With enough enqueue operations (a bit more than two billion) the int value of
inwill overflow and become negative! The modulo (or ‘remainder’) operator % preserves the sign. Thus you might end up writing intob[-14]for example!
这时候可以运用 bitwise 技巧来实作:
A compact form is correct uses bit masking provided N is 2^x (16,32,64,…)
| |
What would happen if the order of pthread_mutex_unlock and sem_post calls were swapped?
- no effect
What would happen if the order of sem_wait and pthread_mutex_lock calls were swapped?
- deadlock
Part 9: Synchronization Across Processes
Most system calls can be
interruptedmeaning that the operating system can stop an ongoing system call because it needs to stop the process.
mutexes and other synchronization primitives can be shared across processes.