
你所不知道的 C 语言: 记忆体管理、对齐及硬体特性
 ccrysisa
ccrysisa不少 C/C++ 开发者听过 “内存对齐” (memory alignment),但不易掌握概念及规则,遑论其在执行时期的冲击。内存管理像是 malloc/free 函数的使用,是每个 C 语言程序设计开发者都会接触到,但却难保充分排除错误的难题。本讲座尝试从硬体的行为开始探讨,希望消除观众对于 alignment, padding, memory allocator 的误解,并且探讨高效能 memory pool 的设计,如何改善整体程序的效能和可靠度。也会探讨 C11 标准的 aligned_alloc。
背景知识
你所不知道的 C 语言: 指针篇
- C99/C11 6.2.5 Types (28)
A pointer to void shall have the same representation and alignment requirements as a pointer to a character type.
- C99/C11 6.3.2.3 Pointers (1)
A pointer to void may be converted to or from a pointer to any object type. A pointer to any object type may be converted to a pointer to void and back again; the result shall compare equal to the original pointer.
使用 void * 必须通过 explict (显式) 或强制转型,才能存取最终的 object,因为 void 无法判断 object 的大小信息。
你所不知道的 C 语言: 函数呼叫篇
glibc 提供了 malloc_stats() 和 malloc_info() 这两个函数,可以查询 process 的 heap 空间使用情况信息。
Memory 金字塔

这个金字塔的层级图提示我们,善用 Cache locality 可以有效提高程式效能。
Understanding virtual memory - the plot thickens
The virtual memory allocator (VMA) may give you a memory it doesn’t have, all in a vain hope that you’re not going to use it. Just like banks today
虚拟内存的管理类似于银行,返回的分配空间未必可以立即使用。memory allocator 和银行类似,可用空间就类似于银行的现金储备金,银行可以开很多支票,但是这些支票可以兑现的前提是这些支票不会在同一时间来兑现,虚拟内存管理也类似,分配空间也期望用户不会立即全部使用。
Understanding stack allocation
This is how variable-length arrays (VLA), and also alloca() work, with one difference - VLA validity is limited by the scope, alloca’d memory persists until the current function returns (or unwinds if you’re feeling sophisticated).
VLA 和 alloca 分配的都是栈 (stack) 空间,只需将栈指针 (sp) 按需求加减一下即可实现空间分配。因为 stack 空间是有限的,所以 Linux 核心中禁止使用 VLA,防止 Stack Overflow 🤣
Slab allocator
The principle of slab allocation was described by Bonwick for a kernel object cache, but it applies for the user-space as well. Oh-kay, we’re not interested in pinning slabs to CPUs, but back to the gist — you ask the allocator for a slab of memory, let’s say a whole page, and you cut it into many fixed-size pieces. Presuming each piece can hold at least a pointer or an integer, you can link them into a list, where the list head points to the first free element.
在使用 alloc 的内存空间时,这些空间很有可能是不连续的。所以此时对于系统就会存在一些问题,一个是内存空间碎片 fragment,因为分配的空间未必会全部使用到,另一个是因为不连续,所以无法利用 Cache locality 来提升效能。
Demand paging explained
Linux 系统会提供一些内存管理的 API 和机制:
- mlock() - lock/unlock memory 禁止某个区域的内存被 swapped out 到磁盘 (只是向 OS 建议,OS 可能不会理会)
- madvise() - give advice about use of memory (同样只是向 OS 建议,OS 可能不会理会)
- lazy loading - 利用缺页异常 (page-fault) 来实现
- copy on write
- 現代處理器設計: Cache 原理和實際影響
- Cache 原理和實際影響: 進行 CPU caches 中文重點提示並且重現對應的實驗
- 針對多執行緒環境設計的 Memory allocator
- rpmalloc 探討
堆 Heap
- Stack Overflow: Why are two different concepts both called “heap”?
Several authors began about 1975 to call the pool of available memory a “heap.”
Data alignment
一个 data object 具有两个特性:
- value
- storage location (address)
alignment vs unalignment
假设硬体要求 4 Bytes alignment,CPU 存取数据时的操作如下:


除此之外,unalignment 也可能会无法充分利用 cache 效能,即存取的数据一部分 cache hit,另一部分 cache miss。当然对于这种情况,cache 也是采用类似上面的 merge 机制来进行存取,只是效能低下。
The n value below always is required to be a small power of two and specifies the new alignment in bytes.
#pragma pack(push[,n])pushes the current alignment setting on an internal stack and then optionally sets the new alignment.#pragma pack(pop)restores the alignment setting to the one saved at the top of the internal stack (and removes that stack entry). Note that#pragma pack([n])does not influence this internal stack; thus it is possible to have#pragma pack(push)followed by multiple#pragma pack(n)instances and finalized by a single#pragma pack(pop).
alignment 与 unalignment 的效能分布:

malloc
malloc 分配的空间是 alignment 的:
- man malloc
The malloc() and calloc() functions return a pointer to the allocated memory, which is suitably aligned for any built-in type.
The block that malloc gives you is guaranteed to be aligned so that it can hold any type of data. On GNU systems, the address is always a multiple of eight on 32-bit systems, and a multiple of 16 on 64-bit systems.
使用 GDB 进行测试,确定在 Linux x86_64 上 malloc 分配的内存以 16 Bytes 对齐,即地址以 16 进制显示时最后一个数为 0。
unalignment get & set
如上面所述,在 32-bit 架构上进行 8 bytes 对齐的存取效能比较高 (远比单纯访问一个 byte 高),所以原文利用这一特性实作了 unaligned_get8 这一函数。
csrc & 0xfffffffc- 向下取整到最近的 8 bytes alignment 的地址
v >> (((uint32_t) csrc & 0x3) * 8)- 将获取的 alignment 的 32-bit 进行位移以获取我们想要的那个字节

而在 你所不知道的 C 语言: 指针篇 中实作的 16-bit integer 在 unalignment 情况下的存取,并没有考虑到上面利用 alignment 来提升效能。
原文 32 位架构的 unalignment 存取有些问题,修正并补充注释如下:
| |
实作 64-bit integer (64 位架构) 的 get & set:
| |
其它逻辑和 32 位机器上类似
- Data Alignment
- Linux kernel: Unaligned Memory Accesses
concurrent-II
使用 CAS 无法确保链表插入和删除同时发生时的正确性,因为 CAS 虽然保证了原子操作,但是在进行原子操作之前,需要在链表中锚定节点以进行后续的插入、删除 (这里是通过 CAS 操作)。如果先发生插入,那么并不会影响后面的操作 (插入或删除),因为插入的节点并不会影响后面操作锚定的节点。但如果先发生删除,那么这个删除操作很有可能就把后面操作 (插入或删除) 已经锚定的节点从链表中删掉了,这就导致了后续操作的不正确结果。所以需要一个方法来标识「不需要的节点」,然后再进行原子操作。
- C99 6.7.2.1 Structure and union specifiers
Each non-bit-field member of a structure or union object is aligned in an implementation defined manner appropriate to its type.
Within a structure object, the non-bit-field members and the units in which bit-fields reside have addresses that increase in the order in which they are declared. A pointer to a structure object, suitably converted, points to its initial member (or if that member is a bit-field, then to the unit in which it resides), and vice versa. There may be unnamed padding within a structure object, but not at its beginning.
所以 C 语言中结构体的 padding 是 implementation defined 的,但是保证这些 padding 不会出现在结构体的起始处。
The alignment of non-bit-field members of structures (C90 6.5.2.1, C99 and C11 6.7.2.1).
Determined by ABI.
- C99 7.18.1.4 Integer types capable of holding object pointers
The following type designates a signed integer type with the property that any valid pointer to void can be converted to this type, then converted back to pointer to void, and the result will compare equal to the original pointer: intptr_t

- Aggregates and Unions
Structures and unions assume the alignment of their most strictly aligned compo- nent. Each member is assigned to the lowest available offset with the appropriate alignment. The size of any object is always a multiple of the object‘s alignment. An array uses the same alignment as its elements, except that a local or global array variable of length at least 16 bytes or a C99 variable-length array variable always has alignment of at least 16 bytes. 4 Structure and union objects can require padding to meet size and alignment constraints. The contents of any padding is undefined.
所以对于链表节点对应的结构体:
| |
因为 data alignment 的缘故,它的地址的最后一个 bit 必然是 0 (成员都是 4-bytes 的倍数以及必须对齐),同理其成员 next 也满足这个性质 (因为这个成员表示下一个节点的地址)。所以删除节点时,可以将 next 的最后一个 bit 设置为 1,表示当前节点的下一个节点已经被“逻辑上”删除了。
最后当没有插入或删除操作是,链表再对标识为“删除”的节点进行移除,这个机制有点类似于 GC
glibc 的 malloc/free 实作
背景考量: Deterministic Memory Allocation for Mission-Critical Linux
Main arena vs Thread arena :
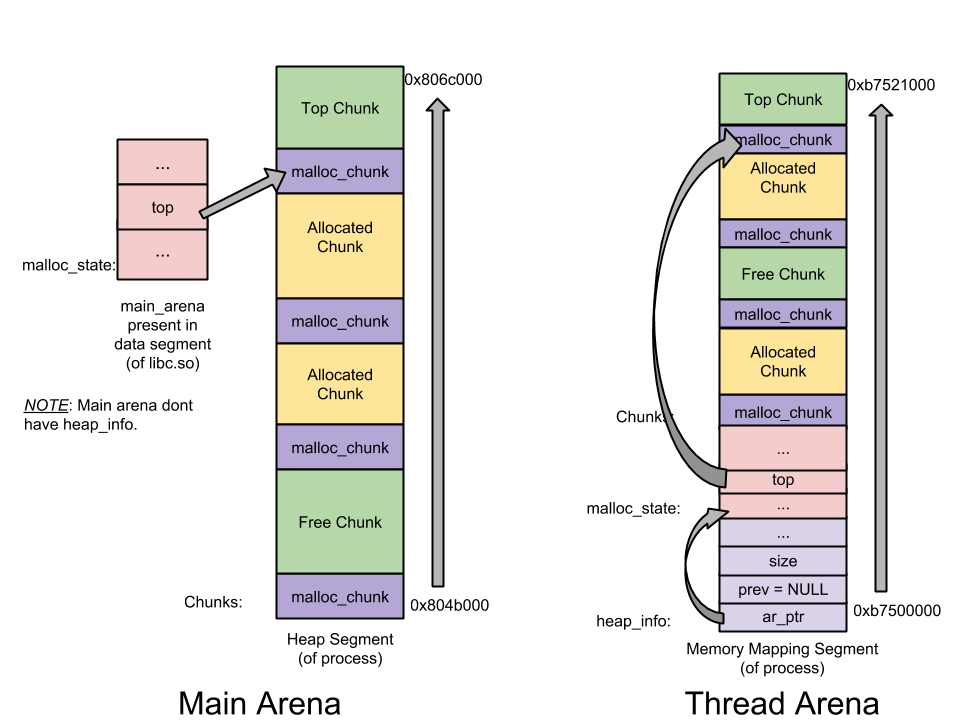
multiple heap Thread arena :